GPU是Graphics Processing Unit(图形处理器)的简称,它是一种专门在个人电脑、工作站、游戏机和一些移动设备(如平板电脑、智能手机等)上运行绘图运算工作的微处理器。图形处理器是NVIDIA公司(NVIDIA)在1999年8月发表NVIDIA GeForce 256(GeForce 256)绘图处理芯片时首先提出的概念,在此之前,电脑中处理影像输出的显示芯片,通常很少被视为是一个独立的运算单元。而对手冶天科技(ATi)亦提出视觉处理器(Visual Processing Unit)概念。图形处理器使显卡减少对中央处理器(CPU)的依赖,并分担部分原本是由中央处理器所担当的工作,尤其是在进行三维绘图运算时,功效更加明显。图形处理器所采用的核心技术有硬件坐标转换与光源、立体环境材质贴图和顶点混合、纹理压缩和凹凸映射贴图、双重纹理四像素256位渲染引擎等。
图形处理器可单独与专用电路板以及附属组件组成显卡,或单独一片芯片直接内嵌入到主板上,或者内置于主板的北桥芯片中,现在也有内置于CPU上组成SoC的。个人电脑领域中,在2007年,90%以上的新型台式机和笔记本电脑拥有嵌入式绘图芯片,但是在性能上往往低于不少独立显卡。但2009年以后,AMD和英特尔都各自大力发展内置于中央处理器内的高性能集成式图形处理核心,它们的性能在2012年时已经胜于那些低端独立显卡,这使得不少低端的独立显卡逐渐失去市场需求,两大个人电脑图形处理器研发巨头中,AMD以AMD APU产品线取代旗下大部分的低端独立显示核心产品线。而在手持设备领域上,随着一些如平板电脑等设备对图形处理能力的需求越来越高,不少厂商像是高通(Qualcomm)、Imagination、ARM、NVIDIA等,也在这个领域“大显身手”。
GPU不同于传统的CPU,如Intel i5或i7处理器,其内核数量较少,专为通用计算而设计。相反,GPU是一种特殊类型的处理器,具有数百或数千个内核,经过优化,可并行运行大量计算。虽然GPU在游戏中以3D渲染而闻名,但它们对运行分析、深度学习和机器学习算法尤其有用。GPU允许某些计算比传统CPU上运行相同的计算速度快10倍至100倍。
本期的智能内参,我们推荐方正证券的报告《GPU研究框架》,从GPU的底层技术、产业链发展情况和国产GPU的自主之路三方面全面解析GPU及其产业。
本期内参来源:方正证券
原标题:
《GPU研究框架》
作者:陈杭 等
一、GPU:专用计算时代的“画师”
GPU(graphics processing unit)图形处理器,又称显示核心、视觉处理器、显示芯片,是一种在个人电脑、工作站、游戏机和一些移动设备(如平板电脑、智能手机等)上做图像和图形相关运算工作的微处理器。GPU通常包括图形显存控制器、压缩单元、BIOS、图形和计算整列、总线接口、电源管理单元、视频管理单元、显示界面。GPU的出现使计算机减少了对CPU的依赖,并解放了部分原本CPU的工作。在3D图形处理时,GPU采用的核心技术有硬件T&L(几何转换和光照处理)、立方环境材质贴图和顶点混合、纹理压缩和凹凸映射贴图、双重纹理四像素256位渲染引擎等,而硬件T&L技术可以说是GPU的标志。

▲GPU的内部组成部分

▲GPU核心及PCB板
GPU的微架构(Micro Architecture)是一种给定的指令集和图形函数集合在处理器中执行的方法。图形函数主要用于绘制各种图形所需要的运算。当前和像素、光影处理、3D坐标变换等相关运算由GPU硬件加速来实现。相同的指令集和图形函数集合可以在不同的微架构中执行,但实施的目的和效果可能不同。优秀的微架构对GPU性能和效能的提升发挥着至关重要的作用,GPU体系是GPU微架构和图形API的集合。
以目前最新的英伟达安培微架构为例,GPU微架构的运算部份由流处理器(Stream Processor,SP)、纹理单元(Texture mapping unit, TMU)、张量单元(Tensor Core)、光线追踪单元(RT Cores)、光栅化处理单元(ROPs)组成。这些运算单元中,张量单元,光线追踪单元由NVIDIA在伏特/图灵微架构引入。
除了上述运算单元外,GPU的微架构还包含L0/L1操作缓存、Warp调度器、分配单元(Dispatch Unit)、寄存器堆(register file)、特殊功能单元(Special function unit,SFU)、存取单元、显卡互联单元(NV Link)、PCIe总线接口、L2缓存、二代高位宽显存(HBM2)等接口。
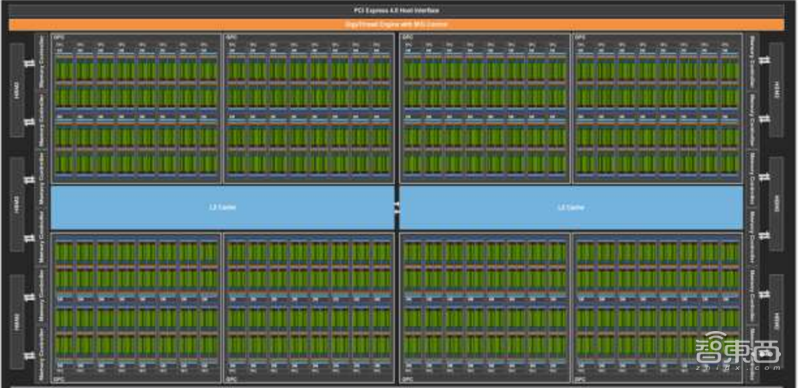
▲英伟达安培内核概览
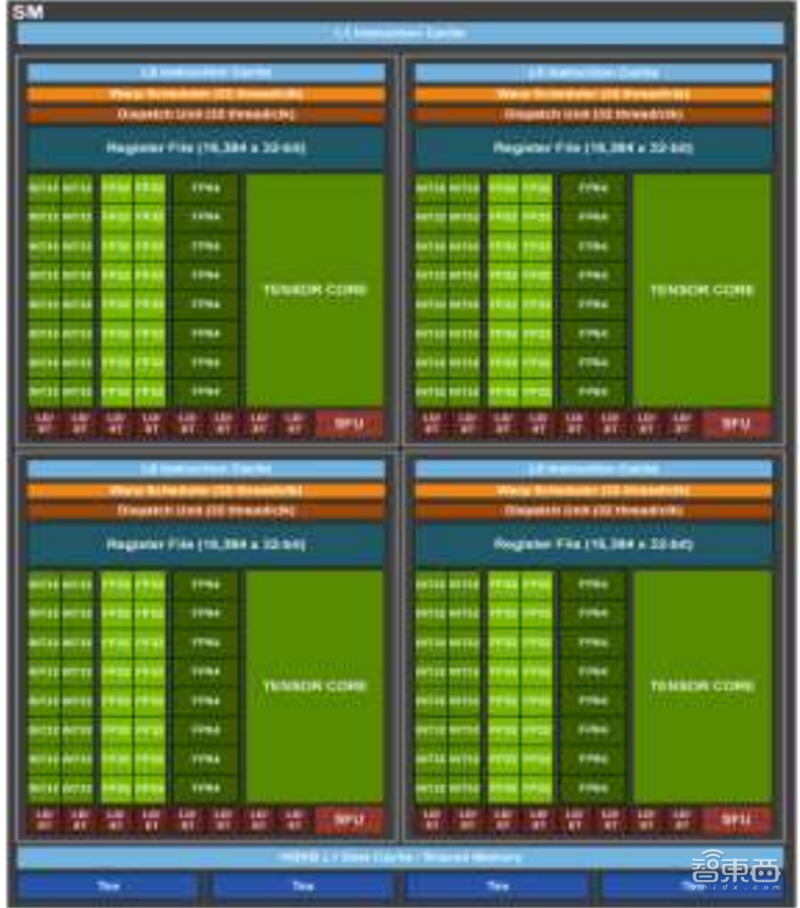
▲英伟达安培内核“SM”单元
GPU的流处理器单元是NVIDIA对其统一架构GPU内通用标量着色器的命名。SP单元是全新的全能渲染单元,是继Pixel Pipelines(像素管线)和Vertex Pipelines(顶点管线)之后新一代的显卡渲染技术指标。SP单元既可以完成VS(Vertex Shader,顶点着色器)运算,也可以完成PS(Pixel Shader,像素着色器)运算,而且可以根据需要组成任意VS/PS比例,从而给开发者更广阔的发挥空间。
流处理器单元首次出现于DirectX 10时代的G80核心的Nvidia GeForce 8800GTX显卡,是显卡发展史上一次重大的革新。之后AMD/ATI的显卡也引入了这一概念,但是流处理器在横向和纵向都不可类比,大量的流处理器是GPU性能强劲的必要非充分条件。
纹理映射单元(TMU)作为GPU的部件,它能够对二进制图像旋转、缩放、扭曲,然后将其作为纹理放置到给定3D模型的任意平面,这个过程称为纹理映射。纹理映射单元不可简单跨平台横向比较,大量的纹理映射单元是GPU性能强劲的必要非充分条件。
光栅化处理单元(ROPs)主要负责游戏中的光线和反射运算,兼顾AA、高分辨率、烟雾、火焰等效果。游戏里的抗锯齿和光影效果越厉害,对ROPs的性能要求就越高,否则可能导致帧数的急剧下降。NVIDIA的ROPs单元是和流处理器进行捆绑的,二者同比例增减。在AMD GPU中,ROPs单元和流处理器单元没有直接捆绑关系。
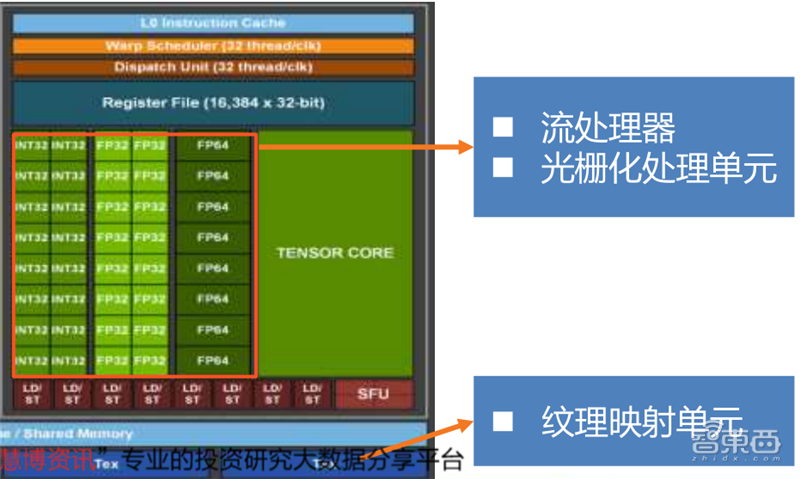
▲英伟达安培内核SP、ROPs、TMU拆解
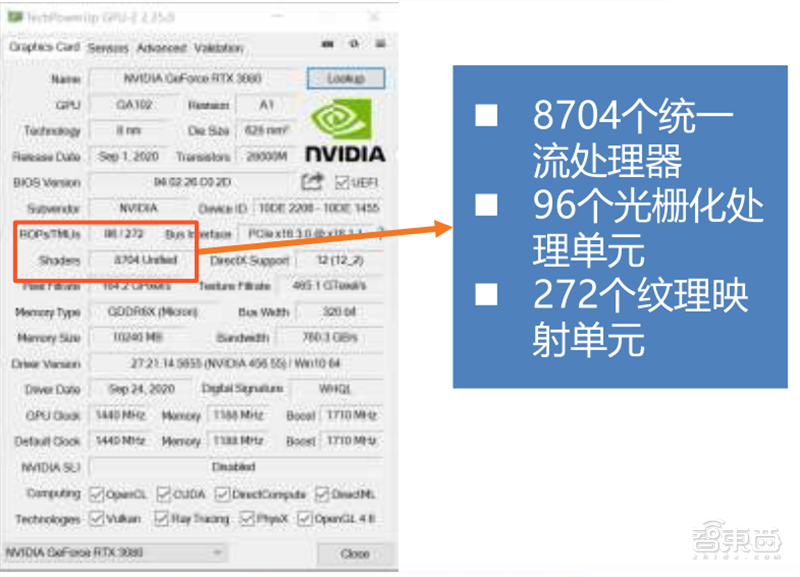
▲英伟达RTX 3080 GPU-Z参数
消费GPU的实时光线追踪在2018年由英伟达的“图灵”GPU首次引入,光追单元(RT Cores)在此过程中发挥着决定性的作用。图灵GPU的光追单元支持边界体积层次加速,实时阴影、环境光、照明和反射,光追单元和光栅单元可以协同工作,进一步提高帧数和阴影的真实感。
光追单元在英伟达的RTX光线追踪技术、微软DXR API、英伟达Optix API和Vulkan光追API的支持下可以充分发挥性能。拥有68个光追单元的RTX2080Ti在光线处理性能上较无光追单元的GTX1080Ti强10倍。
张量单元(Tensor Core)在2017年由英伟达的“伏特”GPU中被首次引入。张量单元主要用于实时深度学习,服务于人工智能,大型矩阵运算和深度学习超级采样(DLSS),可以带来惊人的游戏和专业图像显示,同时提供基于云系统的快速人工智能。
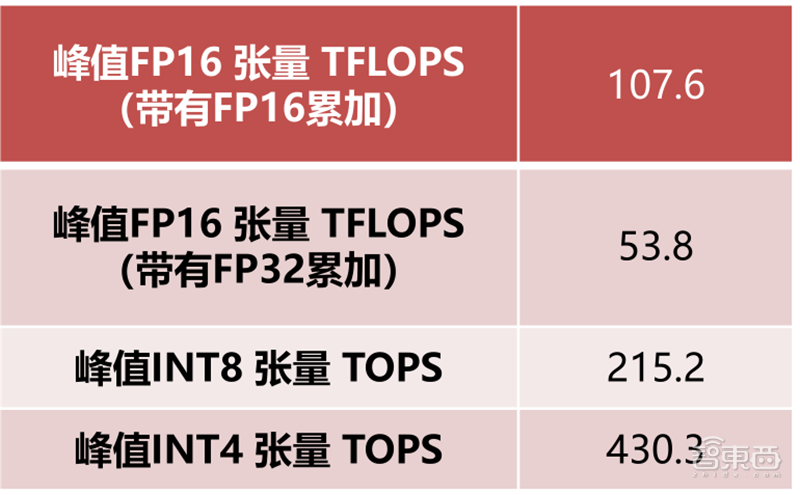
▲英伟达RTX2080Ti张量单元算力
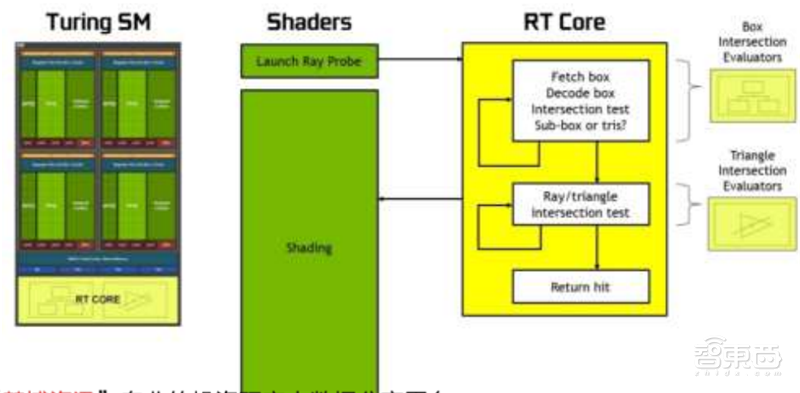
▲英伟达图灵GPU光追单元运作流程
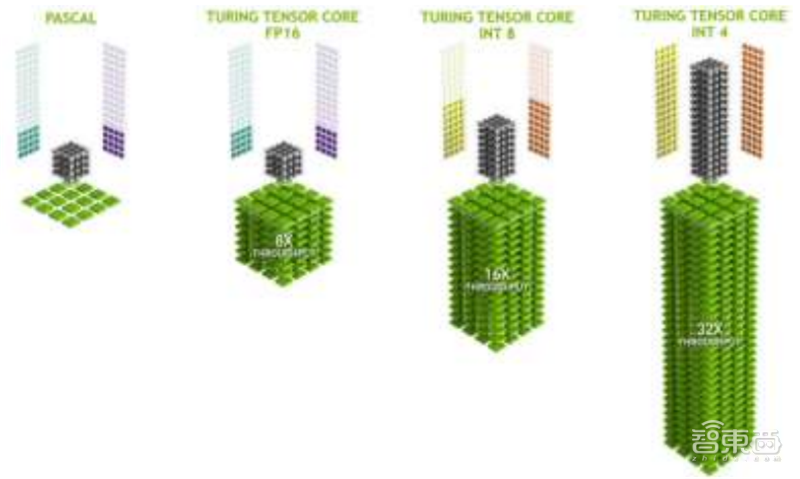
▲英伟达图灵GPU张量单元提供多精度AI
GPU的API(Application Programming Interface)应用程序接口发挥着连接应用程序和显卡驱动的桥梁作用。不过随着系统优化的深入,API也可以直接统筹管理高级语言、显卡驱动和底层汇编语言。
3D API能够让编程人员所设计的3D软件只需调动其API内的程序,让API自动和硬件的驱动程序沟通,启动3D芯片内强大的3D图形处理功能,从而大幅地提高3D程序的设计效率。同样的,GPU厂家也可以根据API标准来设计GPU芯片,以达到在API调用硬件资源时的最优化,获得更好的性能。3D API可以实现不同厂家的硬件、软件最大范围兼容。如果没有API,那么开发人员必须对不同的硬件进行一对一的编码,这样会带来大量的软件适配问题和编码成本。
目前GPU API可以分为2大阵营和若干其他类。2大阵营分别是微软的DirectX标准和KhronosGroup标准,其他类包括苹果的Metal API、AMD的Mantle(地幔)API、英特尔的One API等。
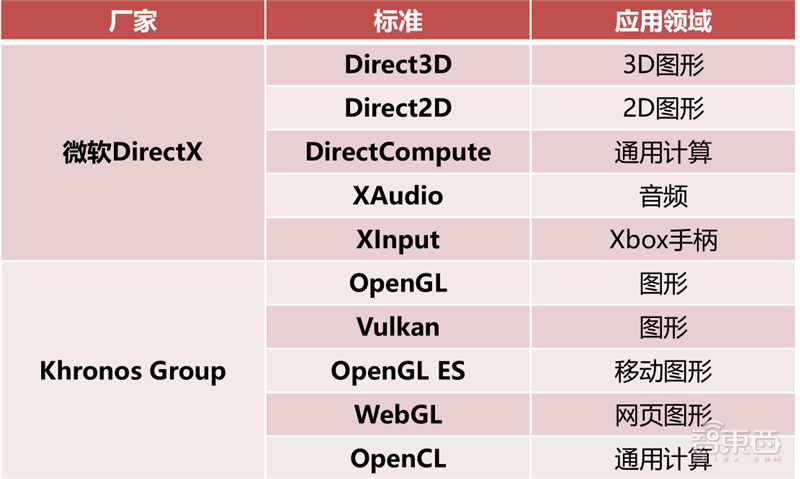
▲微软DirectX和Khronos Group API组合对比
DirectX是Direct eXtension的简称,作为一种API,是由微软公司创建的多媒体编程接口。DirectX可以让以Windows为平台的游戏或多媒体程序获得更高的执行效率,加强3D图形和声音效果,并提供设计人员一个共同的硬件驱动标准,让游戏开发者不必为每一品牌的硬件来写不同的驱动程序,也降低用户安装及设置硬件的复杂度。DirectX已被广泛使用于Windows操作系统和Xbox主机的电子游戏开发。
OpenGL是Open Graphics Library的简称,是用于渲染2D、3D矢量图形的跨语言、跨平台的应用程序编程接口(API),相比DirectX更加开放。这个接口由近350个不同的函数调用组成,用来绘制从简单的二维图形到复杂的三维景象。OpenGL常用于CAD、虚拟现实、科学可视化程序和电子游戏开发。
正是由于OpenGL的开放,所以它可以被运行在Windows、MacOS、Linux、安卓、iOS等多个操作系统上,学习门槛也比DirectX更低。但是,效率低是OpenGL的主要缺点。
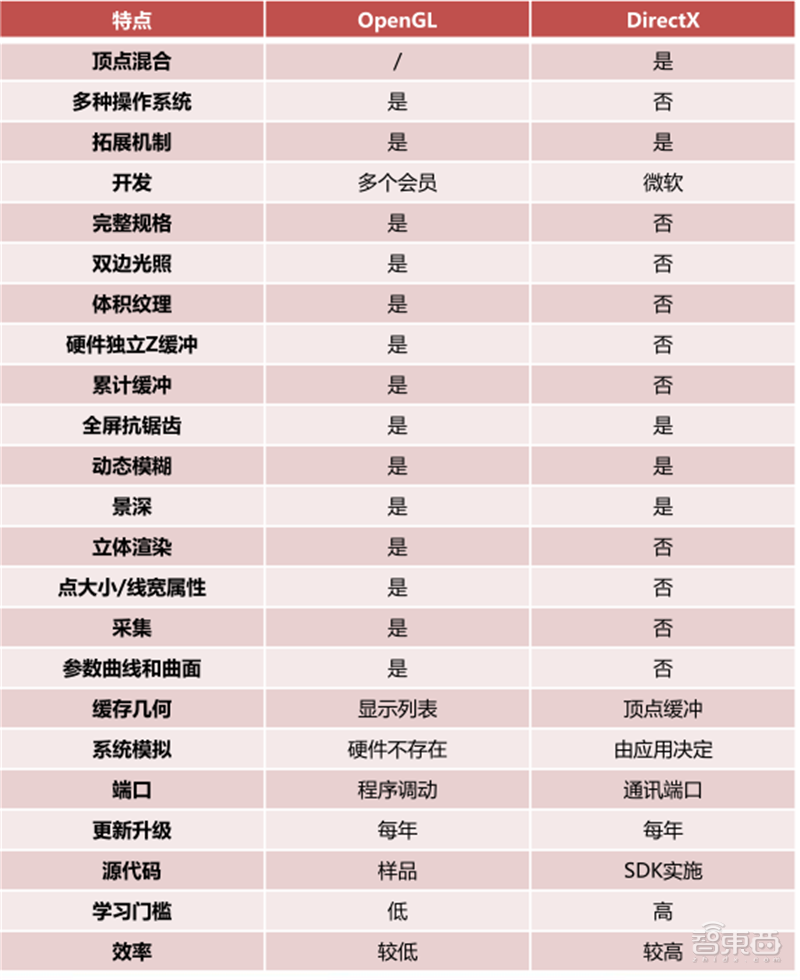
▲DirectX和OpenGL特点对比
Metal是Apple在2014年创建的接近底层的,低开销的硬件加速3D图形和计算着色器API。Metal在iOS 8中首次亮相。Metal在一个API中结合了类似于OpenGL和OpenCL的功能。它旨在通过为iOS,iPadOS,macOS和tvOS上的应用程序提供对GPU硬件的底层访问来提高性能。相较于OpenGL ES,Metal减少了10倍的代码拥挤,提供了更好的解决方案,并将会在苹果设备中取代OpenGL。Metal也支持英特尔HD和IRIS系列GPU、AMD的GCN和RDNA GPU、NVIDIA GPU。Metal也是可以使用Swift或Objective-C编程语言调用的面向对象的API。GPU的全部操作是通过Metal着色语言控制的。
2017年,苹果推出了Metal的升级版Metal2,兼容前代Metal硬件,支持iOS11,MacOS和tvOS11。Metal2可以在Xcode中更有效地进行配置和调试,加快机器学习速度,降低CPU工作量,在MacOS上支持VR,充分发挥A11 GPU的特性。
Vulkan是一种低开销,跨平台的3D图像和计算API。Vulkan面向跨所有平台的高性能实时3D图形应用程序,如视频游戏和交互式媒体。与OpenGL,Direct3D 11和Metal相比,Vulkan旨在提供更高的性能和更平衡的CPU/GPU用法。除了较低的CPU使用外,Vulkan还旨在使开发人员更好地在多核CPU中分配工作。
Vulkan源自并基于AMD的Mantle API组件,最初的版本被称为OpenGL的下一代。最新的Vulkan1.2发布于2020年1月15日,该版本整合了23个额外经常被使用的Vulkan拓展。

▲Metal与OpenGL性能对比
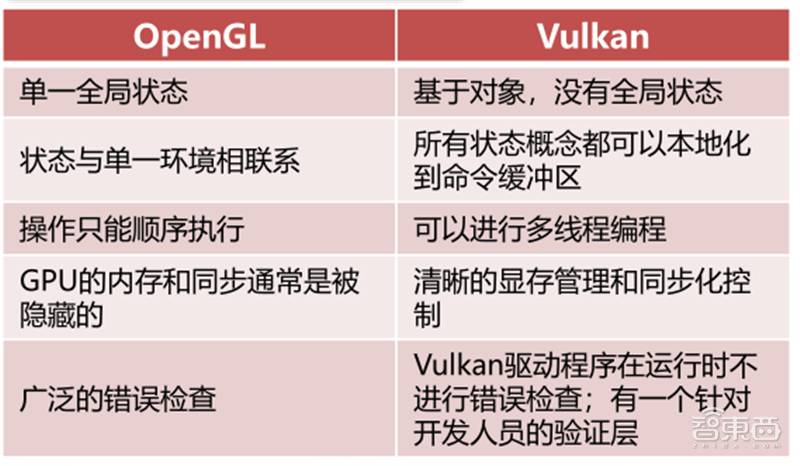
▲OpenGL和Vulkan对比
软件生态方面,GPU无法单独工作,必须由CPU进行控制调用才能工作,而CPU在处理大量类型一致的数据时,则可调用GPU进行并行计算。所以,GPU的生态和CPU的生态是高度相关的。
近年来,在摩尔定律演进的放缓和GPU在通用计算领域的高速发展的此消彼长之下,通用图形处理器(GPGPU)逐渐“反客为主”,利用GPU来计算原本由CPU处理的通用计算任务。
目前,各个GPU厂商的GPGPU的实现方法不尽相同,如NVIDIA使用的CUDA(compute unified device architecture)技术、原ATI的ATI Stream技术、Open CL联盟、微软的DirectCompute技术。这些技术可以让GPU在媒体编码加速、视频补帧与画面优化、人工智能与深度学习、科研领域、超级计算机等方面发挥异构加速的优势。以上4种技术中,只有OpenCL支持跨平台和开放标注的特性,还可以使用专门的可编程电路来加速计算,业界支持非常广泛。
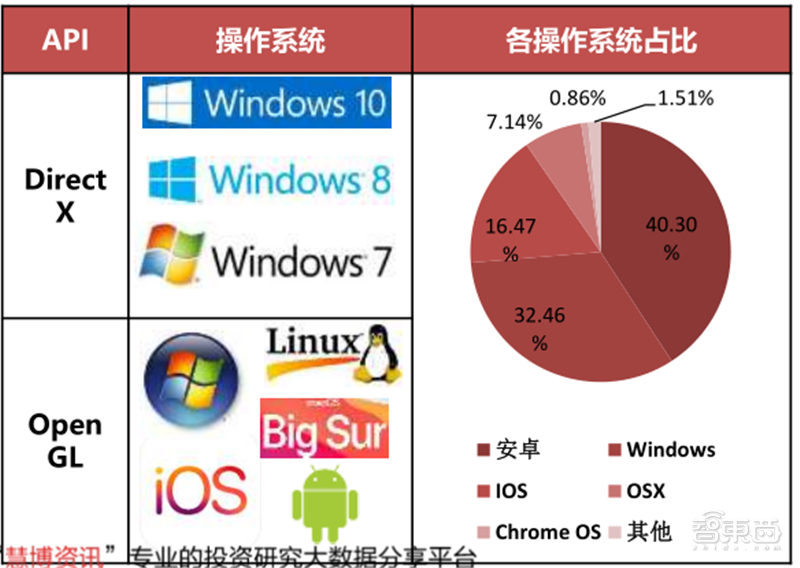
▲DirectX和OpenGL生态对比

▲OpenCL联盟生态
GPU根据接入方式可以划分为独立GPU和集成GPU。独立GPU一般封装在独立的显卡电路板上,拥有独立显存,而集成GPU常和CPU共用一个Die,共享系统内存。GPU根据接入方式可以划分为独立GPU和集成GPU。独立GPU一般封装在独立的显卡电路板上,拥有独立显存,而集成GPU常和CPU共用一个Die,共享系统内存。
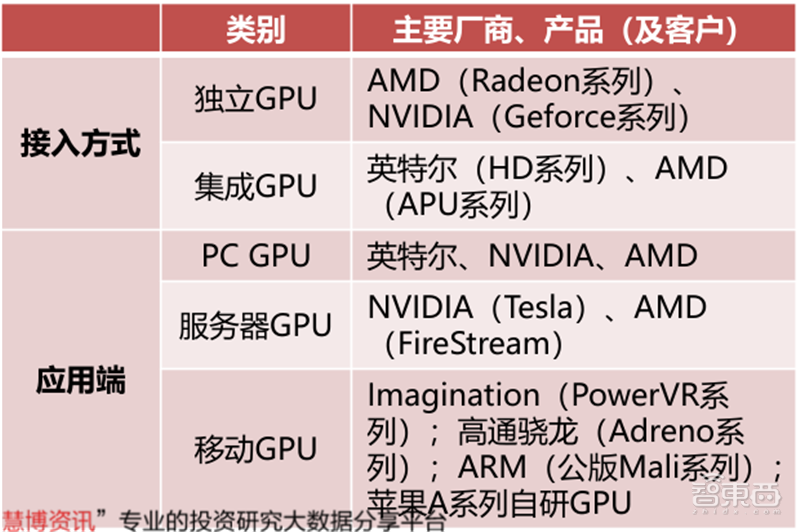
▲GPU的主要分类

▲独立GPU

▲集成GPU Die
GPU显存是用来存储显卡芯片处理过或者即将提取的渲染数据,是GPU正常运作不可或缺的核心部件之一。GPU的显存可以分为独立显存和集成显存两种。目前,独立显存主要采用GDDR3、GDDR5、GDDR5X、GDDR6,而集成显存主要采用DDR3、DDR4。服务器GPU偏好使用Chiplet形式的HBM显存,最大化吞吐量。
集成显存受制于64位操作系统的限制,即便组成2通道甚至4通道,与独立显存的带宽仍有相当差距。通常这也造成了独立GPU的性能强于集成GPU。
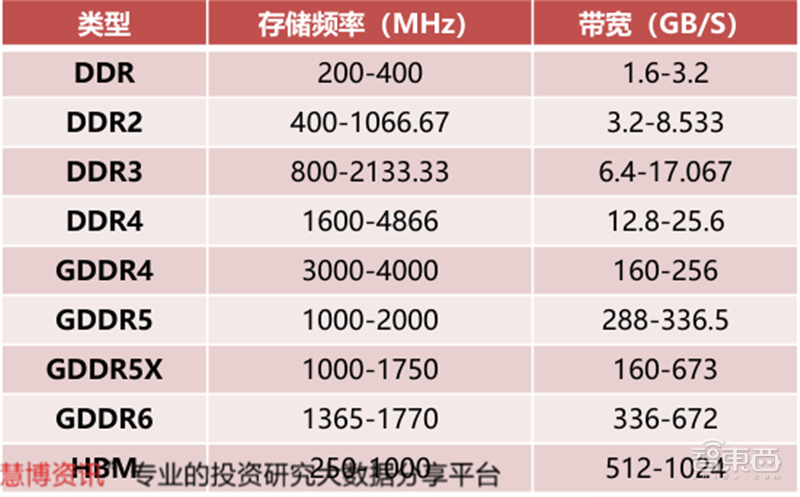
▲显存的主要分类
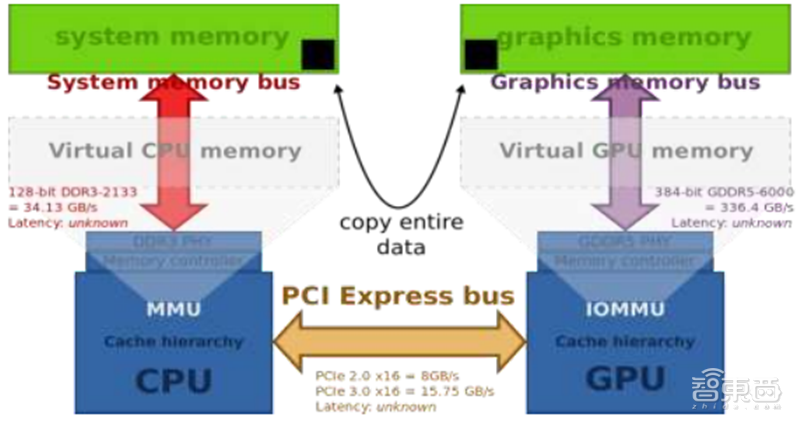
▲独立显存的工作方式
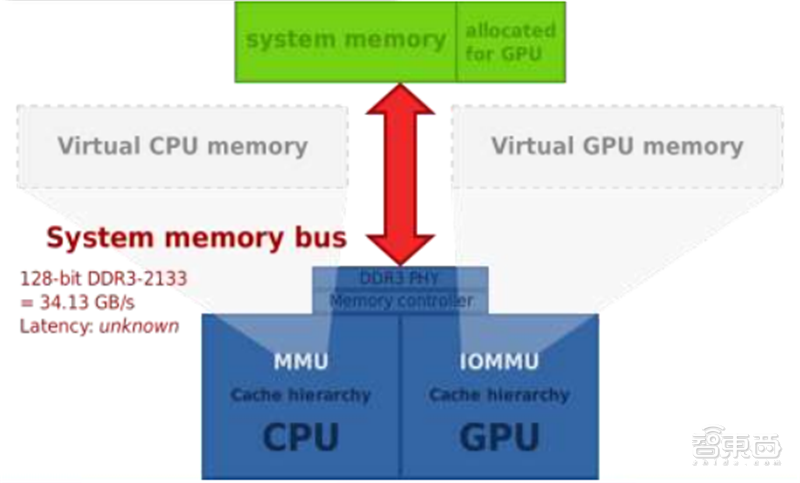
▲独立显存的工作方式
集成显卡是指一般不带显存,而是使用系统的一部分主内存作为显存的显卡。集成显卡可以被整合进主板作为北桥芯片的一部分,也可以和CPU集成在同一个Die中。集成显卡的显存一般根据系统软件和应用软件的需求自动调整。如果显卡运行需要占用大量内存空间,那么整个系统运行会受限,此外系统内存的频率通常比独立显卡的显存低很多,因此集成显卡的性能比独立显卡要逊色一些。
独立显卡是将显示芯片及相关器件制作成一个独立于电脑主板的板卡,成为专业的图像处理硬件设备。独立显卡因为具备高位宽、高频独立显存和更多的处理单元,性能远比集成显卡优越,不仅可用于一般性的工作,还具有完善的2D效果和很强的3D水平,因此常应用于高性能台式机和笔记本电脑,主要的接口为PCIe。
如今,独立显卡与集成显卡已经不是2个完全割裂,各自为营的图像处理单元了。二者在微软DX12的支持下也可以实现独核显交火,同时AMD和NVIDIA的显卡也可实现混合交火。
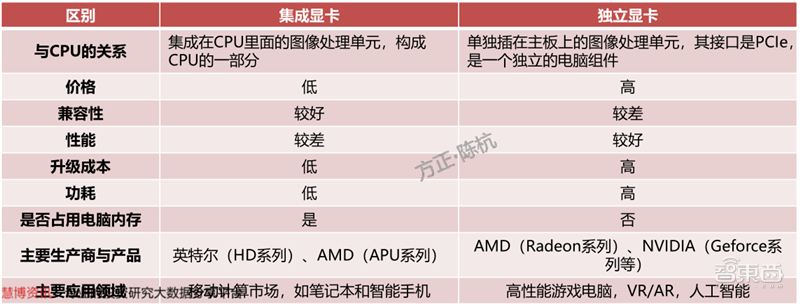
▲集成显卡和独立显卡对比
GPU对比CPU:从芯片设计思路看,CPU是以低延迟为导向的计算单元,通常由专为串行处理而优化的几个核心组成,而GPU是以吞吐量为导向的计算单元,由数以千计的更小、更高效的核心组成,专为并行多任务设计。
CPU和GPU设计思路的不同导致微架构的不同。CPU的缓存大于GPU,但在线程数,寄存器数和SIMD(单指令多数据流)方面GPU远强于CPU。
微架构的不同最终导致CPU中大部分的晶体管用于构建控制电路和缓存,只有少部分的晶体管完成实际的运算工作,功能模块很多,擅长分支预测等复杂操作。GPU的流处理器和显存控制器占据了绝大部分晶体管,而控制器相对简单,擅长对大量数据进行简单操作,拥有远胜于CPU的强大浮点计算能力。
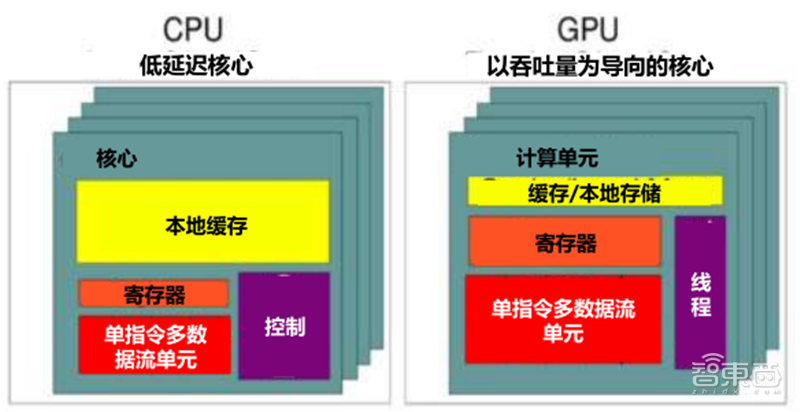
▲GPU和CPU的核心设计思路对比

▲GPU和CPU的核心对比
后摩尔时代,随着GPU的可编程性不断增强,GPU的应用能力已经远远超出了图形渲染,部份GPU被用于图形渲染以外领域的计算成为GPGPU。与此同时,CPU为了追求通用性,只有少部分晶体管被用于完成运算,而大部分晶体管被用于构建控制电路和高速缓存。但是由于GPU对CPU的依附性以及GPU相较CPU更高的开发难度,所以GPU不可能完全取代CPU。我们认为未来计算架构将是GPU+CPU的异构运算体系。
在GPU+CPU的异构运算中,GPU和CPU之间可以无缝地共享数据,而无需内存拷贝和缓存刷新,因为任务以极低的开销被调度到合适的处理器上。CPU凭借多个专为串行处理而优化的核心运行程序的串行部份,而GPU使用数以千计的小核心运行程序的并行部分,充分发挥协同效应和比较优势。
异构运算除了需要相关的CPU和GPU等硬件支持,还需要能将它们有效组织的软件编程。OpenCL是(OpenComputing Language)的简称,它是第一个为异构系统的通用并行编程而产生的统一的、免费的标准。OpenCL支持由多核的CPU、GPU、Cell架构以及信号处理器(DSP)等其他并行设备组成的异构系统。
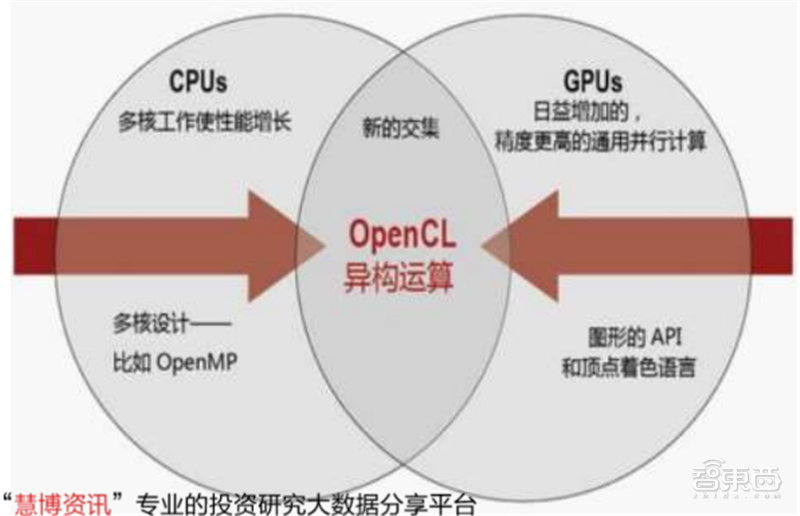
▲OpenCL异构运算构成
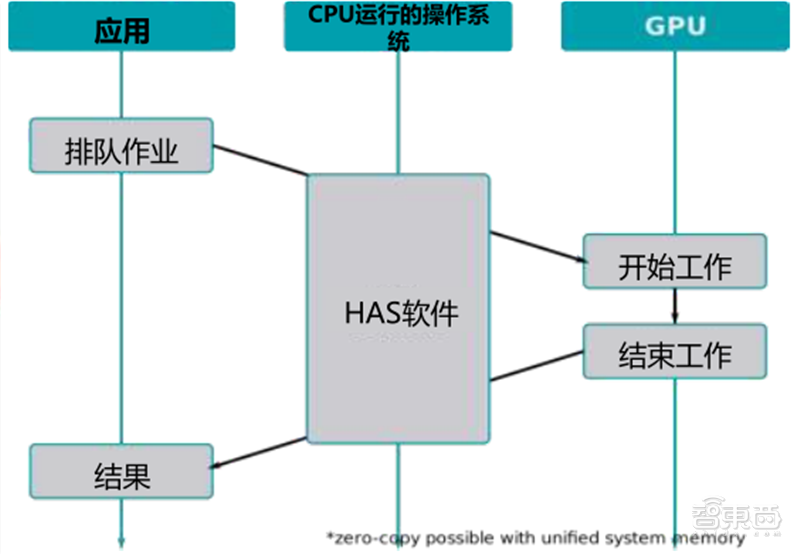
▲异构运算下的GPU工作流程
GPU与ASIC和FPGA的对比:数据、算力和算法是AI三大要素,CPU配合加速芯片的模式成为典型的AI部署方案,CPU提供算力,加速芯片提升算力并助推算法的产生。常见的AI加速芯片包括GPU、FPGA、ASIC三类。
GPU用于大量重复计算,由数以千计的更小、更高效的核心组成大规模并行计算架构,配备GPU的服务器可取代数百台通用CPU服务器来处理HPC和AI业务。
FPGA是一种半定制芯片,灵活性强集成度高,但运算量小,量产成本高,适用于算法更新频繁或市场规模小的专用领域。
ASIC专用性强,市场需求量大的专用领域,但开发周期较长且难度极高。
在AI训练阶段需要大量数据运算,GPU预计占64%左右市场份额,FPGA和ASIC分别为22%和14%。推理阶段无需大量数据运算,GPU将占据42%左右市场,FPGA和ASIC分别为34%和24%。
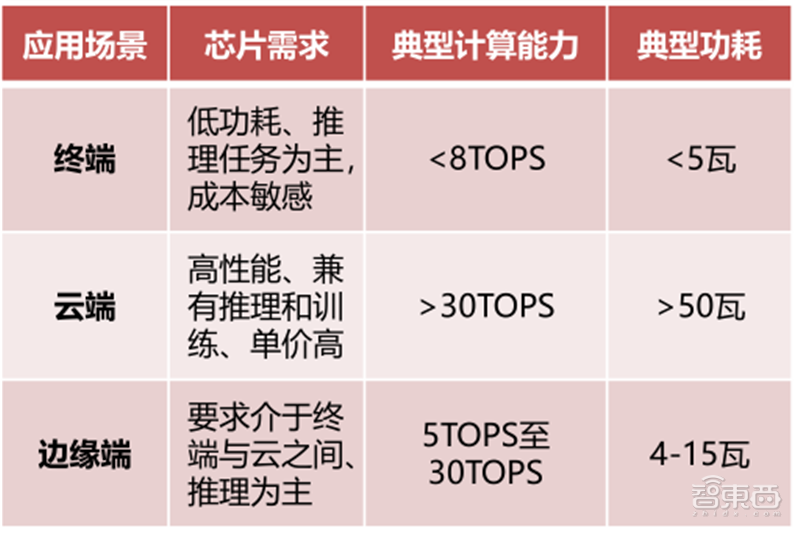
▲不同应用场景AI芯片性能需求和具体指标
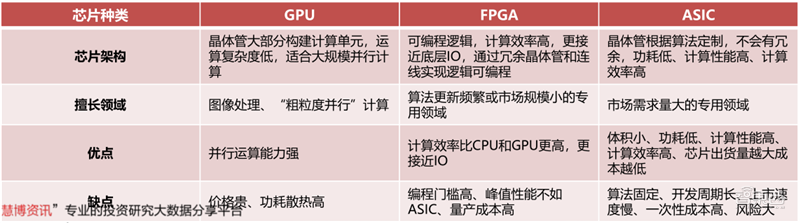
▲GPU、FPGA、ASIC AI芯片对比
在PC诞生之初,并不存在GPU的概念,所有的图形和多媒体运算都由CPU负责。但是由于X86 CPU的暂存器数量有限,适合串行计算而不适合并行计算,虽然以英特尔为代表的厂商多次推出SSE等多媒体拓展指令集试图弥补CPU的缺陷,但是仅仅在指令集方面的改进不能起到根本效果,所以诞生了图形加速器作为CPU的辅助运算单元。
GPU的发展史概括说来就是NVIDIA、AMD(ATI)的发展史,在此过程中曾经的GPU巨头Imagination、3dfx、东芝等纷纷被后辈超越。如今独立显卡领域主要由英伟达和AMD控制,而集成显卡领域由英特尔和AMD控制。
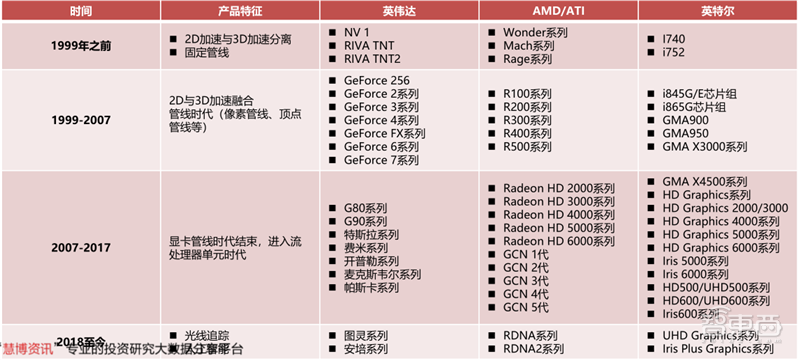
▲GPU的发展史
英伟达的GPU架构自2008年以来几乎一直保持着每2年一次大更新的节奏,带来更多更新的运算单元和更好的API适配性。在每次的大换代之间,不乏有一次的小升级,如采用开普勒二代微架构的GK110核心相较于采用初代开普勒微架构的GK104核心,升级了显卡智能动态超频技术,CUDA运算能力提升至3.5代,极致流式多处理器(SMX)的浮点运算单元提升8倍,加入了Hyper-Q技术提高GPU的利用率并削减了闲置,更新了网格管理单元(Grid Management Unit),为动态并行技术提供了灵活性。
英伟达GPU微架构的持续更新,使英伟达GPU的能效提升了数十倍,占领了独立显卡技术的制高点。
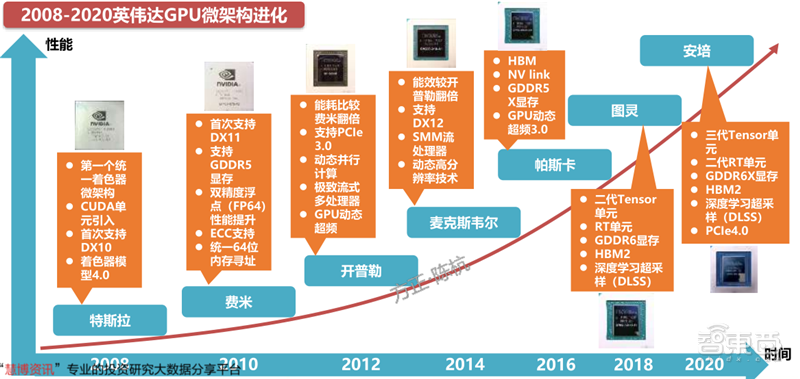
▲2008-2020英伟达GPU微架构进化
图形API在GPU的运算过程中发挥着连接高级语言、显卡驱动乃至底层汇编语言的作用,充当GPU运行和开发的“桥梁”和“翻译官”。微软DirectX标准可以划分为显示部份、声音部份、输入部分和网络部分,其中与GPU具有最直接关系的是显示部分。显示部份可分为DirectDraw和Direct3D等标准,前者主要负责2D图像加速,后者主要负责3D效果显示。
从1995年发布的初代DirectX 1.0开始微软的DirectX已经更新到了DirectX 12。在此过程中,DirectX不断完善对各类GPU的兼容,增加开发人员的权限,提高GPU的显示质量和运行帧数。
DirectX一般和Windows操作系统同步更新,如Windows 7推出了DX11、Windows 10推出了DX12。

▲1998-2014微软DirectX进化
GPU和CPU都是以先进制程为导向的数字芯片。先进制程可以在控制发热和电能消耗的同时,在有限的Die中放入尽可能多的晶体管,提高GPU的性能和能效。
NVIDIA的GPU从2008年GT200系列的65纳米制程历经12年逐步升级到了RTX3000系列的7/8纳米制程,在整个过程中,晶体管数量提升了20多倍,逐步确立了在独立GPU的市场龙头地位。
同时在整个过程中,NVIDIA一直坚持不采用IDM的模式,而是让台积电负责GPU的制造,自生专注于芯片设计,充分发挥比较优势。
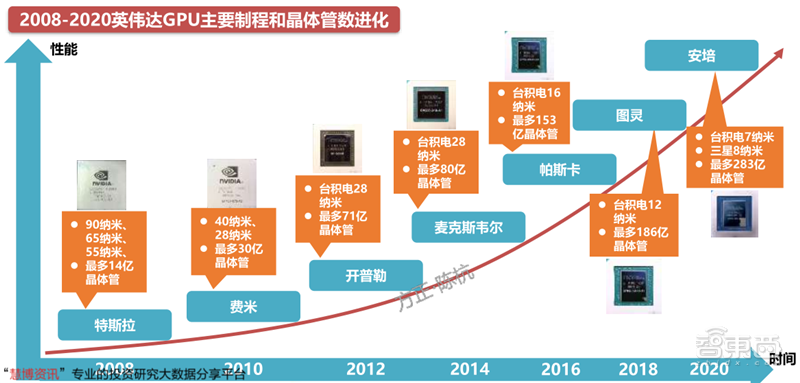
▲2008-2020英伟达GPU主要制程和晶体管数进化
根据前12年的GPU发展轨迹来看,GPU微架构的升级趋势可以简要地概括为”更多”、”更专”、”更智能”。“更多”是指晶体管数量和运算单元的增加,其中包括流处理器单元、纹理单元、光栅单元等数量上升。“更专”是指除了常规的计算单元,GPU还会增加新的运算单元。例如,英伟达的图灵架构相较于帕斯卡架构新增加了光追单元和张量单元,分别处理实时光线追踪和人工智能运算。“更智能”是指GPU的AI运算能力上升。如第三代的张量单元相较于上代在吞吐量上提升了1倍。
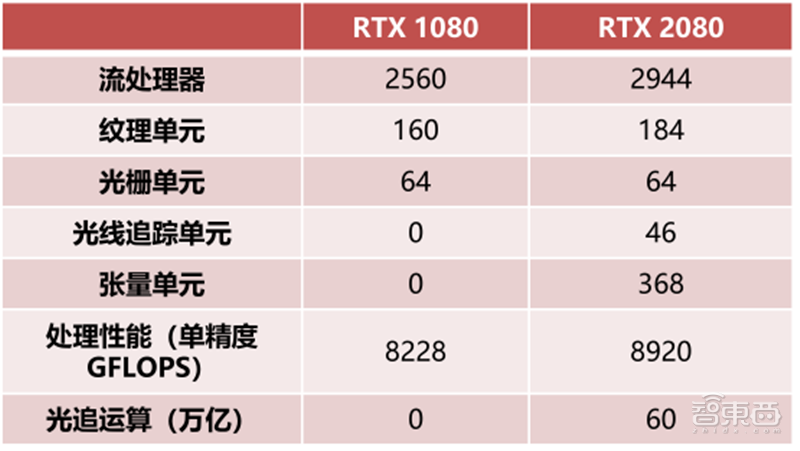
▲英伟达GTX1080对比RTX2080
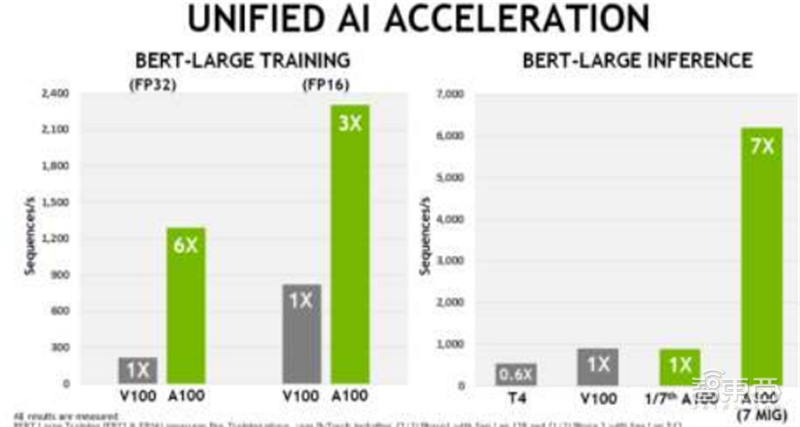
▲英伟达伏特微架构对比安培微架构AI加速性能

▲英伟达安培架构提升
综合分析微软的DirectX12、苹果的Metal2、Khronos Group的Vulkan API分别相较于前代DirectX11、Metal、OpenGL的升级,我们认为GPU API的升级趋势是提高GPU的运行效率、增加高级语言和显卡驱动之间的连接、优化视觉特效等。其中,提供更底层的支持:统筹高级语言、显卡驱动和底层语言是几乎所有API升级的主要方向。
不过提供更底层的支持只是更高的帧数或更好的画质的必要非充分条件。在整个软件的开发过程中,软件开发商需要比驱动程序和系统层更好地调度硬件资源,才能充分发挥底层API的效果。
在显示质量方面,DirectX 12 Ultimate采用当下最新的图形硬件技术,支持光线追踪、网格着色器和可变速率着色,PC和Xbox共用同一个API,堪称次世代游戏的全新黄金标准。
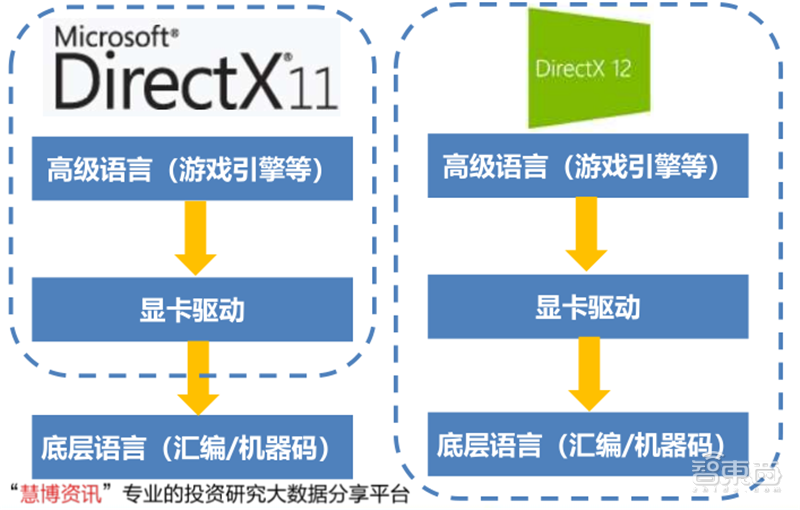
▲非底层DirectX 11对比底层DirectX 12
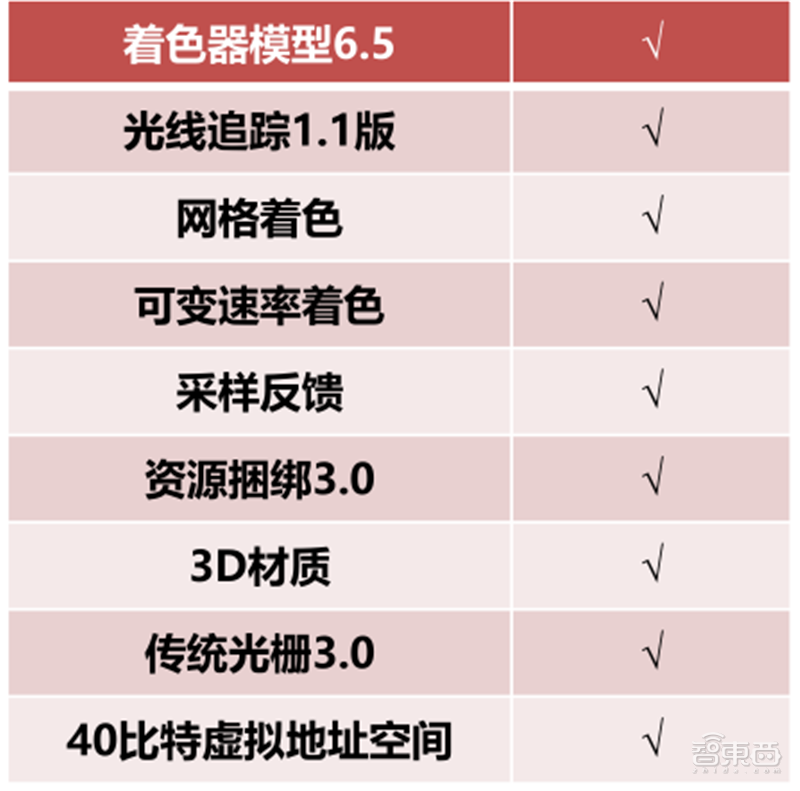
▲DirectX 12 Ultimate新特性
GPU制造升级趋势:以先进制程为导向。GPU性能的三大决定因素为主频、微架构、API。这些因素中主频通常是由GPU的制程决定的。制程在过去通常表示晶体管或栅极长度等特征尺寸,不过出于营销的需要,现在的制程已经偏离了本意,因此单纯比较纳米数没有意义。按英特尔的观点,每平方毫米内的晶体管数(百万)更能衡量制程。据此,台积电和三星的7nm工艺更接近英特尔的10nm工艺。
先进的制程可以降低每一个晶体管的成本,提升晶体管密度,在GPU Die体积不变下实现更高的性能;先进制程可以提升处理器的效能,在性能不变的情况下,减少发热或在发热不变的情况下,通过提升主频来拉高性能。
先进制程的主要目的是降低平面结构带来的漏电率问题,提升方案可以通过改变工艺,如采用FinFET(鳍式场效应晶体管)或GAA(环绕式栅极);或采用特殊材料,如FD-SOI(基于SOI的超薄绝缘层上硅体技术)。
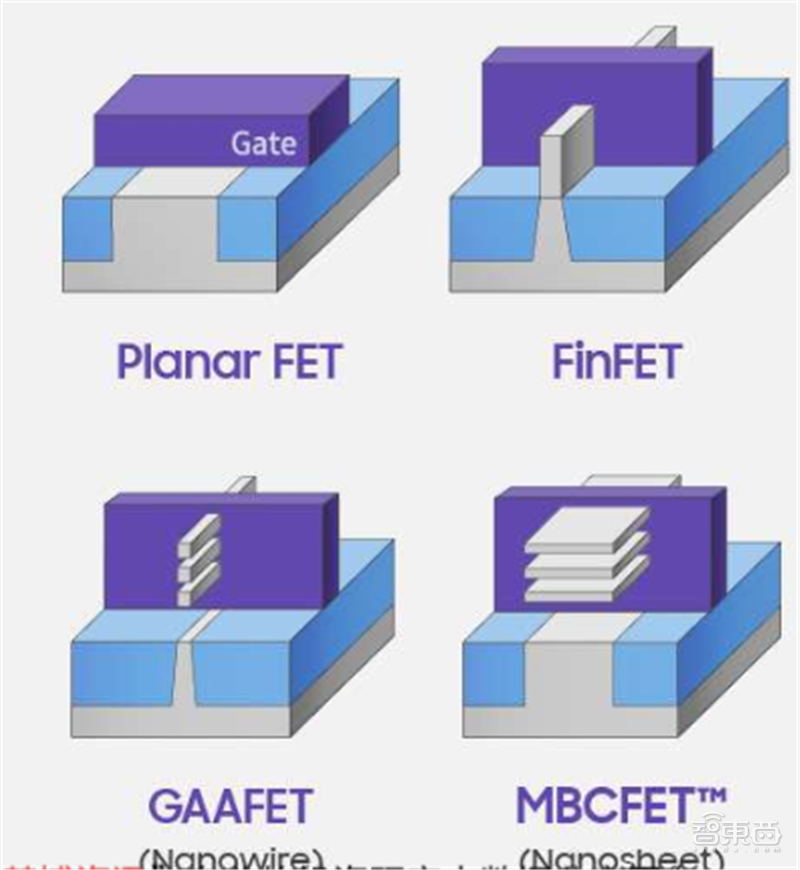
▲先进制程工艺之FinFET
评论
发表评论